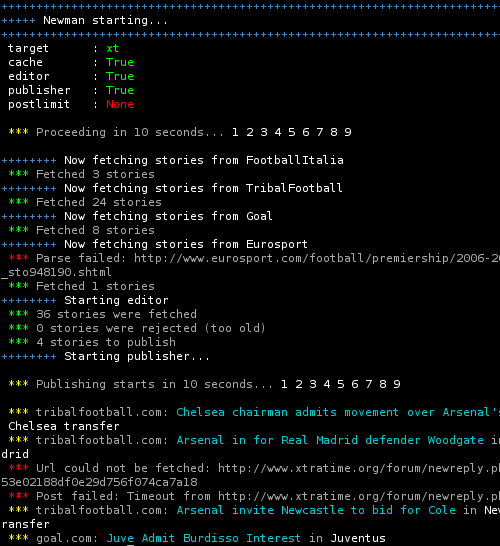
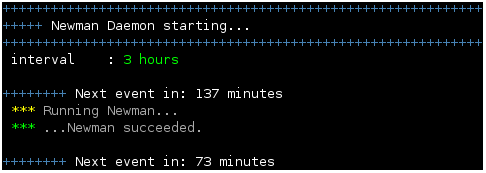
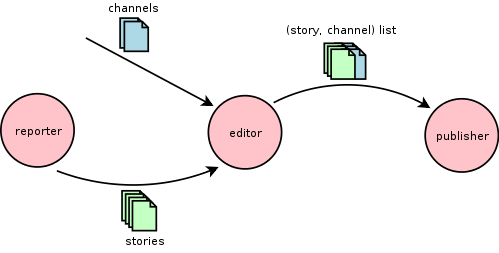
The editor is basically the "brain" of Newman. It's the most complicated part, because it has to handle the most logic. Broadly speaking, it is the editor's job to figure out which news articles to post where. Once the target is set (ie. Xtratime.org), the editor has to figure out whether each of the articles delivered by the reporter should be published in any of the channels (ie. threads) we have available. The illustration below shows the editor's role in the chain.
Finding channels
But before we dive right into it, a small note on channels is in order. Let's start with a rather more basic question: How does a human post news articles? Carson35 will post articles wherever the particular story is relevant - either to the thread at large, or to the last few posts specifically. The question is whether Newman can imitate this behavior. Xtratime.org is divided into lots of forums, one for each club, where threads about that one club are found. Some of these forums have special threads active all through the season, like for instance a "transfer rumours" thread. So what should Newman do to decide where to post an article? It could iterate over the threads in a certain forum to figure out "what this thread is about". But that is rather difficult to do, for a bot. Given just one sentence, how do you mechanically establish such a terribly human observation - what it's "about"? If Newman could do this, it would be quite clever. But, I must admit that I can't think of a method.
So, the approach I took was to input a list of channels manually selected. I can't think of a way to establish what a post is about, or a thread is about, or if a certain story should be posted in a specific thread. So I had to fall back on a human method and simply give Newman a list of threads it can use to post articles in.
The subject filter
So I've built Newman to do all the tedious work for me, but I've already had to produce the channels myself, it would be nice if Newman could do some work too now. Given the channels, we now have a bunch of stories and a bunch of channels - how do we match them? I've selected my channels so that I have one channel per club forum. One thread to post news articles in is already enough to aggravate sensitive forum people, so I'm not going to push my luck. This also means that I have to figure out if a certain story is about a certain club, or not. This I call the subject filter (ie. to establish the subject of the story).
If you think this is already getting hazy, unfortunately it doesn't get any better. I'm not at all interested in trying to deduce the meaning of sentences in English (this would likely take me around forever to finish). Instead, I'm limiting myself to just looking at individual words. So while a complete analysis would reveal that the phrase "the royal club" may be talking about Real Madrid, I won't be getting into that. I will limit myself to looking for just words. Now, it may seem prudent that in order to establish that a story talks about a certain club, it would be helpful to look for the names of players who play for that club. But players change clubs all the time, so the list of players for every club would have to be updated every so often (and remember: we're trying to minimize the human input here). Worse still, half the stories in the papers about Real Madrid discuss possible signings of players who belong to other clubs. To consider adding all players linked with a club to the list of players at every club would be mad.
So, the only thing I will use is the one name that doesn't ever change: the name of the club itself. In its many incarnations. So a story that mentions "Real Madrid" is one that we probably want to classify as eligible for the Real Madrid channel. But it could also just mention Real or Madrid on their own, so we have to consider that too. But then again, Real could also refer to Real Zaragoza, so then "Real" should be a weaker match than "Real Madrid". As you can probably see by now, this is going in the direction of a spam filter: searching for words and scoring them according to certain rules. In addition, it struck me that the position of a word in a text tends to mean something (if it's in the beginning of the story, or in the title, it should give a higher score). Finally, the length of a story matters as well. In a typical story of the kind we like to analyze, the name of a club may appear 2-3 to 5 times. In a very short story, it may only appear once. In a very long story, it may appear more times, in the guise of nicknames and phrases like "the royal club". So a long story may mention Real Madrid 3 times, but may actually be about Barcelona, so we will not give "Real Madrid" as high a score as it would get in a shorter story.
Getting a bit hazy, is it? I thought it might. The subject filter works fairly well in most cases. There have been occasional whoopsies, like a story about Arsenal de Sarandí posted in the Arsenal (the English one) forum. And there was a story about Luis Valencia matching the Valencia channel. I have tried to filter this by searching for Valencia as part of a name (ie. as part of a sequence of capitalized words) - and penalizing that match under suspicion for being the name of a person - but this kind of thing is very imprecise.
The topic filter
So far so good (do I sense hesitation?). For some channels it is enough to use the subject filter. But for others, those which have to do with transfer rumours, we should also decide whether a certain story is about possible transfers. (Incidentally, most soccer news is.) For this I created a separate filter. So that a story matching on "Real Madrid" would then have to pass through the topic filter to see if it seems to be transfer news. For this I used a word list - a list of words that are highly relevant to transfers, such as contract and offer. Then I scored these words just like I did with the subject filter and set the threshold after some trial and error to filter stories fairly reliably. In any case, I would rather filter out more stories wrongly than to post irrelevant news (just like a spam filter would rather allow more spam than to risk losing your non-spam email). This way, some transfer news didn't make the cut, but afterall there are enough stories published everyday to suffice.
Is that all?!?
So finally, after running every story through the subject filter, and if need be the topic filter, I would have a list of stories to publish in certain channels. A story would rarely qualify for more than 2 channels (a transfer from one club to another), it would most often just qualify for one. In addition, the editor filters out stories by date - any story older than 24h is marked outdated.
The proper cherry on the cake would be to create a Channel Finder module - to find channels automatically. But after having thought about this for a few weeks, I still can't think of a way to do it that would assure any kind of half-decent success rate. Certainly not without trying to analyze English language to some extent, which would be incredibly complicated, if even the least bit effective.
This entry is part of the series Project Newman.

 August 29th, 2006
August 29th, 2006