The answer is no, and here's why you shouldn't feel peer pressured into saying yes.
I was reading about disassembly recently when I came across this nugget:
(...) how can a disassembler tell code from data?
The problem wouldn't be as difficult if data were limited to the .data section of an executable and if executable code were limited to the .code section of an executable, but this is often not the case. (...) A technique that is often used is to identify the entry point of an executable, and find all code reachable from there, recursively. This is known as "code crawling".
(...)
The general problem of separating code from data in arbitrary executable programs is equivalent to the halting problem.
Well, if we can't even do *that*, what can we do?
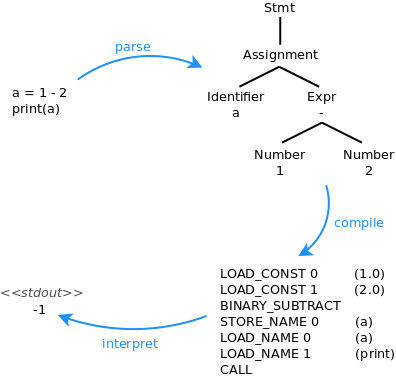
We start with a program you wrote, awesome. We know that part. We compile it. Your favorite language constructs get desugared into very ordinary looking code - all the art you put into your program is lost! Abstract syntax tree, data flow analysis, your constants are folded and propagated, your functions are inlined. By now you wouldn't even know that it's the same program, and we're still in "high level language" territory (probably some intermediate language in the compiler). Now we get basic blocks and we're gonna lay them out in a specific order. This is where the compiler tries to play nice with the branch prediction in your cpu. Your complicated program aka "my ode to control flow" now looks very flat - because it's assembly code. And at last we assemble into machine code - the last vestiges of intelligent life (function names, variable names, any kind of symbolic information) are lost and become just naked memory addresses.
Between your program and that machine code... so many levels. And at each level there are ways to optimize the code. And all of those optimizations have just happened while you stared out the window just now.
So I started thinking about how programs execute. The fact is that predicting the exact execution sequence of a program, even in C, even in C 101 (no pointers, no threading) is basically impossible. Okay, I'm sure it's possible, but I'd have to know the details of my exact cpu model to have a chance.
I need to know how big the pre-fetch cache is. I bet there are some constants that control exactly how the out of order execution engine works - I need to know those. And I need to know the algorithms that are used there (like branch prediction, remember?). I need to know... oh shoot, multicore! Haha, multicore is a huge problem.
Basically, I need to know exactly what else is running on my system at this very time, because that's gonna wreak havoc with my caches. If my L1 gets hosed by another process that's gonna influence a load from memory that I was just about do. Which means I can't execute this instruction I was going to. So I have to pick some other instructions I have lying around and execute those speculatively while we wait for that delivery truck to return all the way from main memory.
Speculatively, you say? Haha yes, since we have these instructions here we'll just go ahead and execute them in case it turns out we needed to do that. Granted, a lot of what a cpu does is stuff like adding numbers, which is pretty easy to undo. "Oops, I 'accidentally' overwrote eax." I guess that addition never happened after all.
And then hyper threading! Do you know how hyper threading works? It's basically a way of saying "this main memory is so damn slow that I can simulate the execution of *two* different programs on a single core and noone's really gonna notice".
This whole thing gives rise to a philosophical question: what is the truth about your program? Is it the effect you observe based on what you read from memory and what you see in the registers (ie. the public API of the cpu)? Or is it the actual *physical* execution sequence of your instructions (the "implementation details" you don't see)?
I remember when virtual machines were starting to get popular around 2000 and there was a lot of discussion about whether they were a good thing - "think about the performance implications". Hell, our so-called physical machines have been virtual for a very long time already!
It's just that the cpu abstraction doesn't seem to leak very much, so you think your instructions are being executed in order. Until you try to use threads. And then you have to ask yourself the deep existential question: what is the memory model of my machine anyway? Just before you start putting memory barriers everywhere.
So no, you don't. But none of your friends do either (unless they work for Intel).

 August 3rd, 2015
August 3rd, 2015